
Lab7
Når vi lager autotester bruker vi stort sett koden deres som en modul, er ikke det kult? Vi importerer funksjonene som vi ber dere skrive, og derfor blir det feil hvis dere har feil navn på funksjonene eller modulene.
Oppgaver
Oppvarming
Obligatorisk
Valgfri
Hvordan fullføre laben
For å bestå laben, må alle de obligatoriske oppgavene være bestått. Laben leveres i CodeGrade; du finner som vanlig knappen dit på mitt.uib.
Oppvarming
Skuddår-modul
Tips: før du løser denne oppgaven bør du lese kursnotatene om moduler, særlig avsnittet om hovedfiler og moduler.
I denne oppgaven skal du lage en modul i filen leapyear.py. Den skal ha en funksjon som forteller hvorvidt et år er et skuddår eller ikke. Modulen du skriver skal både kunne kjøres som et eget program hvor brukeren blir bedt om å oppgi hvilken år hen vil vite mer om, i tillegg til at man skal kunne importere funksjonen is_leap_year til bruk i andre moduler.
Husker du oppgaven om skuddår fra lab2? Her er en repetisjon av reglene:
- Vanligvis er et år som er delelig med 4 et skuddår (for eksempel 1996 var et skuddår);
- bortsett fra år som også er delelige med 100 (for eksempel 1900 er ikke skuddår);
- men hvis året som er delelige med 100 også er delelig med 400, da er det et skuddår likevel (for eksempel er 2000 et skuddår).
Del A
- I filen leapyear.py, lag en funksjon is_leap_year som tar inn et årstall
yearog returnererTruehvis året er et skuddår, ogFalseellers. Ta utgangspunkt i følgende kode du kan kopiere inn i filen din:
def is_leap_year(year):
# TODO: skriv din kode for del A her
# (har du allerede gjorde oppgaven i lab 2, kan du kopiere derfra)
...
def main():
# TODO: skriv din kode for del B her
...
if __name__ == "__main__":
# Vi kaller main kun hvis *denne* filen kjøres som hovedprogrammet
main()
Du kan allerede nå sjekke at det fungerer å bruke programmet ditt som en modul. Last ned scriptet leapyear_test_A.py, legg det i samme mappe som leapyear.py, og kjør det.
Del B
I denne delen av oppgaven skal vi gjøre det mulig å kjøre leapyear.py som et program som en sluttbruker kan benytte. Programmet skal:
- be brukeren om å skrive inn et årstall,
- lese inn hva brukeren skriver (inkludert å konvertere til heltall),
- kalle på funksjonen fra del A for å avgjøre om årstallet er et skuddår eller ikke, og til slutt
- skrive ut om året er et skuddår eller ikke til skjermen. Se eksempler under for nøyaktig ordlyd.
Eksempel på interaksjoner med programmet:
Skriv inn et årstall:
1996
1996 er et skuddår
Skriv inn et årstall:
1800
1800 er ikke et skuddår
Pass på at leapyear_test_A.py fortsatt fungerer!
Relaterte refleksjonsspørsmål vi forventer at du kan svare på under en eventuell eksamen (diskuter gjerne med en venn/en gruppeleder/på discord om du er usikker):
- Hva er hensikten med
if __name__ == "__main__":?- Hva er forskjellen hvis vi fjerner
if __name__ == "__main__":og rett og slett bare kaller påmain()uansett?
Polynom
Forberedelser: Gjør tutorial for pyplot
I denne oppgaven skal du lage en funksjon som bruker matplotlib til å visualisere en andregradsfunksjon. I filen function_visualiser.py lag en funksjon plot_polynomial som tar inn koeffisientene a, b og c til en andregradsfunksjon, og en samling med tall xs som angir x-verdiene som skal plottes. Funksjonen skal plotte funksjonen for disse x-verdiene med matplotlib. Vi skal også sette navn på aksene og gi plottet en tittel. Aksenavnene kan være “x” og “y”, og tittelen kan være “The function f(x) = ax^2 + bx + c” hvor du setter inn riktige verdier for a, b og c.
Husk at en andregradsfunksjon er gitt ved formelen: $$f(x) = ax^2 + bx + c$$
For å teste funksjonen, legg til dette på slutten av filen (gitt at du har importert matplotlib ved import matplotlib.pyplot as plt):
import matplotlib.pyplot as plt
def visualise(a, b, c, xs):
# TODO: din kode her
...
if __name__ == "__main__":
visualise(1, -5, 100, [-10, -8, -6, -4, -2, 0, 2, 4, 6, 8, 10])
plt.show()
Du skal da få en funksjon som ser slik ut om du har gjort det riktig:
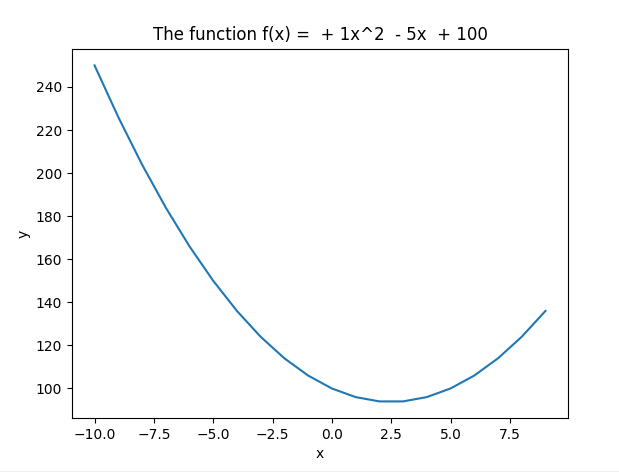
Siden det ser litt rart ut å ha “0x^2” i tittelen når a = 0, eller " + -3x" når b = -3, kan du lage en funksjon som setter riktig fortegn foran konstantene a, b og c i tittelen. Her er forslag til en måte å gjøre det på:
def constant_string(constant):
if constant == 0:
return ""
elif constant > 0:
return f" + {constant}"
else:
return f" - {abs(constant)}"
Du får fortsatt 1-ere foran, slik som “1x” og “1x^2”. Vi har latt være å fikse akkurat dette for å holde det enkelt.
Du kan da bruke f-strengen:
f'The function f(x) = {constant_string(a)}x^2 {constant_string(b)}x {constant_string(c)}'
Som tittel på plottet. Prøv å forstå logikken i krøllparantesene, men det er greit om du ikke gjør det. Det er bare en måte å få riktig fortegn på konstantene.
I funksjonen plot_function kan du gjøre følgende:
- Regn ut y-verdiene for alle x-verdiene i
xsved å bruke formelen for en andregradsfunksjon. - Bruk
plt.plot(xs, ys)for å plotte funksjonen hvoryser y-verdiene du regnet ut i steg 1. - Sett nan
- Bruk
plt.titleog en f-string for å sette tittel. På grunn av fortegnene blir det litt kluss når du får negative konstanter, så se gjerne på hintet over for å få det til.
Tilfeldig bursdag
På forhånd bør du lese om:
Det er også nyttig å søke opp eksempelkode for å se hvordan disse bibliotekene brukes.
I denne oppgaven skal du lage en funksjon som finner en tilfeldig bursdag i et år. I filen random_birthday.py, lag en funksjon random_birthday som tar inn et årstall year og returnerer en tilfeldig dato i det året som en streng. Du kan bruke datetime og random for å lage en dato og utføre addisjon slik at du får en tilfeldig dato i det gitte året. For at testene skal fungere, må du bruke random slik at du genererer en dag i et år basert på dager fra 1.januar. For eksempel vil datoen bli 30.januar hvis du legger til 29 dager, eller 1. januar hvis du legger til 0 dager. Du må ta hensyn til skuddår.
Vi ønsker at datoen skal returneres som en string på formatet dd.mm.yyyy, og til dette kan vi bruke strftime fra datetime. Denne funksjonen gjør et datetime-objekt om til en string, og argumentet spesifiserer formatet. %d gir dag, %m gir måned og %Y gir år.
Siden vi skal vite hvor mange dager det er i året, må vi ta hensyn til skuddår. Hvis du har gjort oppvarmingsoppgaven Skuddår-modul, kan du importere funksjonen is_leap_year fra der. Hvis ikke, se hintet under.
def is_leap_year(year):
return year % 4 == 0 and (year % 100 != 0 or year % 400 == 0)
I funksjonen random_birthday kan du gjøre følgende:
- Bruk datetime til å lage et
datetime-objekt som representerer 1. januar iyear. - Bruk
timedeltaog random til å legge til et tilfeldig antall dager til dette objektet. - Bruk
strftimefor å returnere datoen som en string.
For å teste funksjonen, legg til dette på slutten av filen (gitt at du har importert datetime og random) og sjekk at du får noen tilfeldige datoer i 2022, 2023 og 1912:
if __name__ == "__main__":
print(random_birthday(2022))
print(random_birthday(2023))
print(random_birthday(1912))
Studentregister
Du har et register med studentdata i en json-fil. I filen student_registry.py skal du lage en funksjon convert_students_to_csv som tar inn en path til en json-fil med studentdata og en path til en csv-fil, og skriver dataen til csv-filen med csv-format. Bruk komma som separator.
students.jsonÅpne filen og se på strukturen. Filen er en dictionary med 1 nøkkel, “students”, som har en liste med dictionaries som verdi. Hver dictionary i listen representerer en student og har nøklene “name”, “area” og “year”. Når du har skrevet dataen til csv-filen, skal den se slik ut:
id,name,area,year
1,Alice,Biology,1
2,Bob,Chemistry,2
3,Charlie,Physics,4
- Lag en funksjon convert_students_to_csv som tar inn en filsti til en json-fil med studentdata og en filsti til en csv-fil.
- Les inn dataen fra json-filen med json.load.
- Gå gjennom
data["students"]med en for-løkke. Da er hvert element i listen en dictionary som representerer en student. - Hent ut verdiene i de forskjellige nøklene til hver sin liste, slik at du får en liste med navn, en liste med studieretninger og en liste med årstall. Da representerer hver indeks den samme studenten i hver liste.
- Åpne csv-filen og skriv dataen til filen med csv-format.
For å teste funksjonen din, legg til den følgende koden på slutten av filen din og sjekk at csv-filen blir skrevet til disk slik som vist over.
if __name__ == "__main__":
convert_students_to_csv("students.json", "students.csv")
Obligatorisk
Fredag 13.
I filen friday_13th.py skriv en funksjon first_friday_13th_after(date) som har som parameter et datetime -objekt. Funksjonenen returnerer et nytt datetime-objekt, som befinner seg på første fredag den 13. etter den gitte datoen. Dersom input-datoen selv er på en fredag den 13., er det neste datoen som skal returneres.
Denne oppgaven skal løses ved hjelp av datetime -modulen fra python sitt standardbibliotek.
Test koden din ved å legge til disse linjene nederst i filen:
print("Tester first_friday_13th_after... ", end="")
# Test 1
result = first_friday_13th_after(datetime(2022, 10, 24))
assert((2023, 1, 13) == (result.year, result.month, result.day))
# Test 2
result = first_friday_13th_after(datetime(2023, 1, 13))
assert((2023, 10, 13) == (result.year, result.month, result.day))
# Test 3
result = first_friday_13th_after(datetime(1950, 1, 1))
assert((1950, 1, 13) == (result.year, result.month, result.day))
print("OK")
-
Se eksempel på bruk av datetime på den offisielle dokumentasjonen for datetime.
-
Kan være lurt å ha en hjelpefunksjon som sjekker om et gitt tidspunkt er på en fredag den trettende.
-
Forsøk å øke datoen med én dag helt til du treffer en dag som er på en fredag den trettende.
Jordskjelv
Du har blitt ansatt av et geologisk firma som skal finne ut de minst trygge stedene i verden å bygge boliger. Oppgaven din er å identifisere steder som har hatt store jordskjelv den siste tiden, slik at informasjonen kan selges til ulike boliginvesteringsfirmaer for at de ikke skal bygge boliger der.
I denne oppgaven skal vi kombinere bruken av hele fem moduler. Tre fra standardbiblioteket (datetime, csv, og json) og to eksterne moduler (requests og matplotlib).
Vi skal i denne oppgaven bruke requests til å laste ned data fra en nettside, og så konvertere dataen til en liste av oppslagsverk med csv-biblioteket. Deretter skal vi plotte den med pyplot fra matplotlib. Så skal vi kombinere dette med data fra en annen fil, og plotte begge deler sammen.
Skriv programmet ditt i filen earthquakes.py.
Del A: last ned data om nylige jordskjelv med requests og datetime
Nettsiden til U.S. Geological Survey har åpent tilgjengelig og oppdaterte jordskjelvdata for hele verden. Ta for eksempel denne URL’en: https://earthquake.usgs.gov/fdsnws/event/1/query?format=csv&starttime=2024-03-11T17%3A14%3A55%2B0000&endtime=2024-03-21T17%3A14%3A55%2B0000&minmagnitude=5.8&orderby=magnitude&limit=5000
Om du får spørsmål om å lagre en fil når du trykker på linken over, bør du lagre den som en .csv-fil; for det er nemlig det du får. Om du åpner filen i en teksteditor (f. eks. VSCode) vil du se at den inneholder jordskjelvdata på .csv -format:
time,latitude,longitude,depth,mag,magType,nst,gap,dmin,rms,net,id,updated,place,type,horizontalError,depthError,magError,magNst,status,locationSource,magSource
2024-03-13T15:13:23.771Z,-5.8705,150.6344,50.416,6,mww,112,33,9.887,0.95,us,us6000milg,2024-03-14T15:22:18.952Z,"65 km ESE of Kimbe, Papua New Guinea",earthquake,8.18,4.68,0.044,49,reviewed,us,us
2024-03-14T21:10:24.838Z,29.8022,-42.6586,10,6,mww,179,57,16.293,0.61,us,us6000miy6,2024-03-18T01:11:06.363Z,"northern Mid-Atlantic Ridge",earthquake,9.76,1.795,0.039,62,reviewed,us,us
2024-03-16T00:14:52.156Z,-58.9182,158.3605,10,5.9,mww,58,55,4.443,0.51,us,us6000mj77,2024-03-17T19:46:20.040Z,"Macquarie Island region",earthquake,10.98,1.829,0.071,19,reviewed,us,us
2024-03-13T18:56:13.292Z,-0.1127,125.2136,26.46,5.8,mww,89,67,2.325,1.16,us,us6000minw,2024-03-14T19:00:56.901Z,"106 km SE of Modisi, Indonesia",earthquake,7.48,4.881,0.068,21,reviewed,us,us
Vi fikk altså en liste med fire jordskjelv. Men hvilke jordskjelv er det egentlig vi får? For å undersøke det, kan vi undersøke URL’en vi brukte for å laste ned dataen. Vi kan dele opp URL’en i flere deler:
https://earthquake.usgs.gov/fdsnws/event/1/queryer basen for URL’en. Dette kaller vi for et «API-endepunkt».?betyr at resten av URL’en angir «query parametere» og tilhørende argumenter. Symbolet&brukes for å skille mellom ulike parametere.format=csvspesifiserer at vi ønsker dataen i .csv-format.starttime=2024-03-11T17%3A14%3A55%2B0000spesifiserer at vi ønsker jordskjelv som finner sted fra og med 11. mars 2024 kl. 17:14:55 UTC. Dette er en måte å skrive tidspunkt på som kalles ISO 8601, men hvor noen symboler har blitt kodet slik at de tryggere kan brukes i en URL (%3Aer en kode for symbolet:og%2Ber en kode for symbolet+).endtime=2024-03-21T17%3A14%3A55%2B0000spesifiserer at vi ønsker jordskjelv som finner sted til og med til 21. mars 2024 kl. 17:14:55 UTC.minmagnitude=5.8er en parameter som spesifiserer at vi ønsker jordskjelv med en styrke på 5.8 eller mer på Richters skala.orderby=magnitudeer en parameter som spesifiserer at vi ønsker jordskjelv sortert etter styrke.limit=5000er en parameter som spesifiserer at vi ønsker maksimalt 5000 jordskjelv.
Det var altså fire jordskjelv som skjedde mellom 11. mars og 21. mars 2024 med en styrke på 5.8 eller høyere, og det er dem vi har fått informasjon om i .csv-filen som vi lastet ned.
For å laste ned data fra internett til et Python-program, bruker vi biblioteket requests.
- Installer
requests - Sjekk at du klarer å laste ned dataen fra URL’en over og skrive den ut i konsollen. Du kan bruke programmet under:
# Rask sjekk for at vi har klart å installere requests -biblioteket
import requests
url = 'https://earthquake.usgs.gov/fdsnws/event/1/query?format=csv&starttime=2024-03-11T17%3A14%3A55%2B0000&endtime=2024-03-21T17%3A14%3A55%2B0000&minmagnitude=5.8&orderby=magnitude&limit=5000'
headers = {'User-Agent': 'inf100.ii.uib.no mitt_uib_brukernavn'}
response = requests.get(url, headers=headers)
content = response.content.decode('utf-8')
print(content)
# Sjekk at du ser csv-dataen fra over i terminalen
Når du har fått dette til, er det på tide å gjøre det litt mer dynamisk; for eksempel ønsker vi å kunne hente ut jordskjelvdata basert på datoen når programmet kjøres. Umiddelbart ser det ut som vi må gjøre en seriøs streng-manipulasjon for å konstruere URL’en vi trenger; men heldigvis har requests-modulen gjort det enkelt å generere URL’er med parametere. For eksempel vil koden under gi nøyaktig samme resultat som koden over. Sjekk at du også får samme resultat!
import requests
baseurl = 'https://earthquake.usgs.gov/fdsnws/event/1/query'
headers = {'User-Agent': 'inf100.ii.uib.no mitt_uib_brukernavn'}
params = {
'format': 'csv',
'starttime': '2024-03-11T17:14:55+0000', # ISO 8601 format
'endtime': '2024-03-21T17:14:55+0000', # ISO 8601 format
'minmagnitude': 5.8,
'orderby': 'magnitude',
'limit': 5000,
}
response = requests.get(baseurl, params=params, headers=headers)
content = response.content.decode('utf-8')
print(content)
Nå virker det forhåpentligvis litt mer overkommelig å generere URL’er slik vi selv ønsker. Det gjenstår bare å kunne lage en ISO 8601-formatert streng for tidspunktet vi ønsker å hente ut jordskjelvdata for. Til dette formålet bruker vi datetime-modulen.
- Opprett et datetime-objekt for sluttidspunktet med tidspunktet «nå» i UTC tid (
datetime.now(timezone.utc)). - Opprett et datetime-objekt for starttidspunktet med tidspunktet 365 dager før sluttidspunktet.
- Konverter til en ISO 8601-formatert streng:
my_iso8601_string = my_datetime_object.strftime('%Y-%m-%dT%H:%M:%S%z') - Bruk disse strengene i request’en din for å hente ut jordskjelvdata for det siste året.
Test at det fungerer. Helt til slutt, skal vi flytte programmet vårt inn i en funksjon, og gjøre det enda mer dynamisk:
- I filen earthquakes.py, skriv en funksjon
get_earthquakes_csv_stringmed to parametre:net antall dager ogmagnitudeet flyttall. Funksjonen skal returnere en CSV-formatert streng med informasjon hentet fra U.S. Geological Survey om alle jordskjelv som har skjedd de sistendagene som hadde en styrke påmagnitudeeller mer. Dersom det er flere enn 5000 slike jordskjelv, skal kun de 5000 sterkeste av dem inkluderes.
# earthquakes.py
import requests
def get_earthquakes_csv_string(n, magnitude):
# Din kode her
...
if __name__ == "__main__":
s = get_earthquakes_csv_string(30, 5.8)
print(s) # vi fjerner print senere, men vi ser nå at vi er på rett vei
Del B: hent ut relevante jordskjelvdata
Vi har så langt fått tak i jordskjelvene som en csv-formatert streng. Nå er tidspunktet for å konvertere fra en slik streng til en liste med oppslagsverk (eller en 2D-liste, om du foretrekker det). Vi kunne kanskje gjort det selv med split og lignende; men legg merke til at CSV-filen kan inneholde komma også i selve stedsnavnene. Da er det ikke så lett å splitte på komma som vi kanskje skulle ønske. Heldigvis har Python en modul for å lese CSV-filer som håndterer dette for oss: csv -modulen.
- Bruk csv-modulen for å konvertere csv-strengen til en liste med oppslagsverk. Strengen benytter komma (
,) som skilletegn («delimiter») og hermetegn (") som grupperingssymbol («quotechar»).
Det vi egentlig ønsker å hente ut fra datasettet er en liste med tupler (lengdegrad, breddegrad, styrke), slik at vi kan plotte punktene.
- I earthquakes.py, lag en funksjon
get_earthquake_listsom tar inn en csv-formatert strengcsv_stringog returnerer en liste med jordskjelv. Hvert jordskjelv skal være en tuple med lengdegrad, breddegrad og styrke som flyttall.
For å teste funksjonen kan du laste ned og kjøre test_get_earthquake_list.py.
Del C: plot jordskjelvdata
Nå som vi har fått tak i dataen vi ønsker, skal vi plotte den med pyplot fra det eksterne biblioteket matplotlib.
I earthquakes.py, lag en funksjon plot_earthquakes som tar inn en liste med koordinater data_points og plotter dem med plt.scatter som blå prikker. Merk at data_points er en liste med tupler (lengdegrad, breddegrad, styrke), mens plt.scatter tar inn to lister xs og ys som henholdsvis inneholder x- og y-verdiene til punktene. Du kan bruke en for-løkke for å hente ut x- og y-verdiene fra data_points og legge dem i hver sin liste.
For å få et bedre inntrykk av hvor jordskjelvene har skjedd, ønsker vi å skalere størrelsen på prikkene etter styrken på jordskjelvet. Dette kan gjøres ved å gi argumentet s til scatter-funksjonen. For å få en synlig størrelsesforskjell, kan du prøve å skalere styrken opphøyd i andre. Dette kan gjøres ved å lage en liste sizes som inneholder styrken opphøyd i andre for hvert jordskjelv, og gi denne listen som argument til s i scatter-funksjonen.
Vi kan også sette alpha=0.3 for å gjøre prikkene litt gjennomsiktige, slik at vi lettere kan se hvor det er flest jordskjelv.
For å teste at alt henger sammen, går vi til if __name__ == '__main__':-blokken som skal være på slutten av filen. Her kaller du først get_earthquakes_string med styrke 4 og 50 dager som argument. Deretter kaller du parse_earthquakes med resultatet av get_earthquakes_string som argument, og så gir du det resultatet til plot_earthquakes. Så kaller du plt.show() for å vise plottet.
Når du er ferdig skal programmet produsere noe som ser noenlunde slik ut (dette ble kjørt 19. mars 2024):
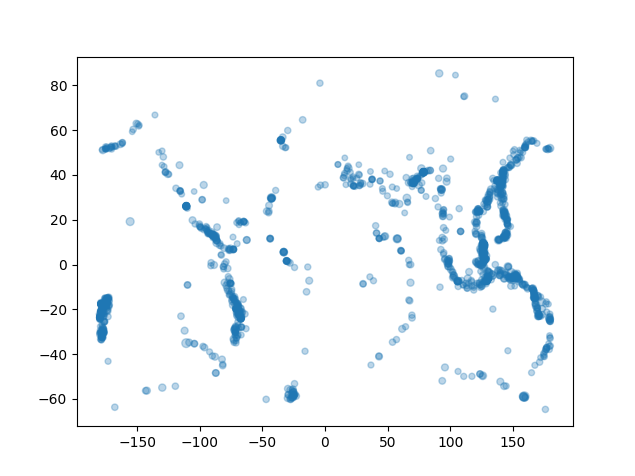
Men dette er jo bare en haug med prikker? Ja, det er jo allerede litt kult, og om vi legger godviljen til kan vi skimte konturene av noen kontinenter og land. Vi ønsker likevel å gi prikkene litt mer mening og kontekst, og dette skal vi gjøre videre.
I funksjonen plot_earthquakes:
- Gå gjennom
datapointsog hent ut x-verdi, y-verdi og styrke for hvert punkt. Legg disse verdiene i hver sin liste, slik at du til slutt ender opp med en liste med x-verdier, en liste med y-verdier, og en liste med styrker. Pass på at styrkene blir opphøyd i andre. - Gi disse verdiene som argumenter til
scatter. Pass på at du må brukes=for å sette listen av styrker inn som størrelser på prikkene. - Sett
alpha=0.3.
Husk at dersom plottet ser feil ut kan det være feil fra Del B eller Del C. Pass på at du gir xs og ys til plt.scatter i riktig rekkefølge, og at du har hentet ut koordinatene riktig i Del B.
Del D: last inn kystlinjer
Ditt neste oppdrag vil være å finne fram et datasett av verdens kystlinjer, og så hente ut dataen vi har behov for slik vi gjorde for jordskjelvene. Først går du til Martyn Afford sitt prosjekt natural-earth-geojson, og laster ned ne_110m_coastline.json fra mappen /110m/physical. Du må klikke på «download raw file» oppe til høyre når du får opp kartet.
Det du har lastet ned nå, er en tekst-fil som inneholder koordinater for hele verdens kystlinjer. Dette er en JSON-fil, som er en måte å lagre data på som er veldig likt Python sine oppslagsverk. En forenklet versjon av filen ser slik ut, hvis vi legger til litt ekstra mellomrom og linjeskift for å gjøre det lettere å lese:
{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"properties": {
"scalerank": 1,
"featurecla": "Coastline",
"min_zooom": 1.0
},
"geometry": {
"type": "LineString",
"coordinates": [
[ -163.71289567772871, -78.595667413241543 ],
[ -159.482404548154477, -79.046337579258974 ],
[ -163.027407803377002, -78.928773695794959 ]
]
}
},
{
"type": "Feature",
"properties": {
"scalerank": 0,
"featurecla": "Coastline",
"min_zooom": 0.0
},
"geometry": {
"type": "LineString",
"coordinates": [
[ -6.197884894220991, 53.867565009163364 ],
[ -9.977085740590269, 51.820454820353078 ],
[ -7.572167934591064, 55.131622219454869 ]
]
}
},
]
}
Om vi tolker data’en som om det var Python-kode, ser vi at den er organisert som et stort oppslagsverk som inneholder lister og andre oppslagsverk. Det er en nøkkel "features" hvor tilhørende verdi er en liste; hvert element i denne listen er én øy (eller verdensdel). Hver slik øy er igjen representert som et oppslagsverk, og har en nøkkel "geometry" hvor verdien igjen er et oppslagsverk som inneholder en nøkkel "coordinates" som inneholder en liste med koordinater. Dette er en liste med punkter som danner en kystlinje.
Anta at
dataer en variabel som inneholder oppslagsverket vist over. Da kan vi hente ut de første koordinatene til den første øyen slik:>>> data['features'][0]['geometry']['coordinates'][0] [-163.71289567772871, -78.595667413241543]Vi kan tolke oppslaget som at vi først åpner «features», så velger vi det første øyen i listen, så åpner vi «geometry» for nevnte øy, så «coordinates», og så henter vi ut det første punktet i listen.
json-modulen fra standardbiblioteket kan brukes for å konvertere en json-streng til et oppslagsverk.
I en funksjon load_coastlines, skal du
- lese inn dataen fra ne_110m_coastline.json som en streng, og
- bruke json-modulen fra standardbiblioteket for å konvertere strengen til et oppslagsverk, og
- returnere en liste med alle øyer. Hver øy skal være representert kun som en liste med koordinater.
Hvis den forenklede JSON-filen over var hele filen, ville altså funksjonen returnert en liste som så slik ut:
[
[ # Første øy
[ -163.71289567772871, -78.595667413241543 ],
[ -159.482404548154477, -79.046337579258974 ],
[ -163.027407803377002, -78.928773695794959 ]
],
[ # Andre øy
[ -6.197884894220991, 53.867565009163364 ],
[ -9.977085740590269, 51.820454820353078 ],
[ -7.572167934591064, 55.131622219454869 ]
]
]
- Les filen og konverter den til et oppslagsverk med json.
- Opprett en tom liste
linessom du skal legge linjene (listene av koordinater) i. - Den øverste nøkkelen i oppslagsverket er
"features". Dette er en liste med kystlinjer. - Iterer over kystlinjene (bruk en for-løkke
for island in data['features']) og hent ut kystlinjene somisland['geometry']['coordinates']. Legg disse linjene til ilines.
Del E: plot kystlinjer
Nå som vi har hentet ut kystlinjene, skal vi plotte dem sammen med jordskjelvdataen. I earthquakes.py, lag en ny funksjon plot_coastlines som tar inn en liste med linjer lines og plotter dem som en linjer med pyplot sin plot-funksjon. Bruk en løkke over linjene for å plotte dem en etter en. Det er ikke så pass mange at det blir en treig løsning slik som i Del C. For å få det til å se ut som eksempelet, må du huske å sette color='grey' som argument til plot-funksjonen. Fargen er ikke et krav, og du får en kul overraskelse om du fjerner color-argumentet.
For å teste funksjonen, kan du legge følgende til i if __name__ == '__main__' -blokken, før kallet til plt.show:
- Et kall til load_coastlines for å laste inn kystlinjene.
- Et kall til plot_coastlines med resultatet fra foregående kall som argument for å plotte kystlinjene.
Når du er ferdig skal programmet produsere noe som ser noenlunde slik ut (hvis du kommenterer bort kallet til plot_earthquakes):
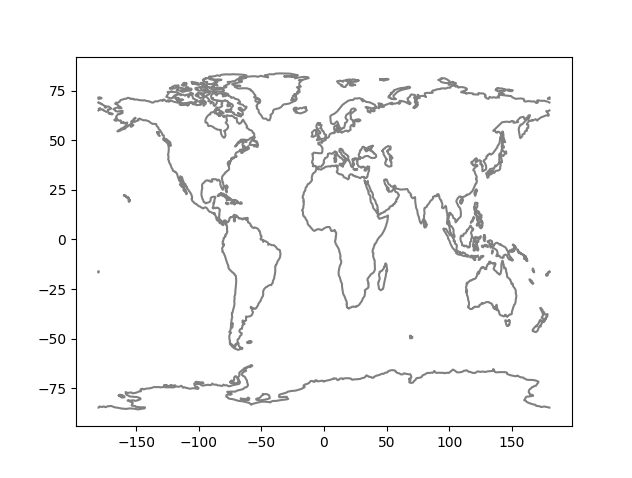
I funksjonen plot_coastlines kan du iterere over lines og hente ut x- og y-verdier for hver linje på samme måte som vi gjorde i del C. Plot linjene med plt.plot for å lage et linjeplot. Bruk color='grey' for å få linjene grå, eller fjern argumentet for en kul overraskelse.
Husk at dersom plottet ser feil ut kan det være feil fra Del D eller Del E. Pass på at du gir xs og ys til plt.plot i riktig rekkefølge, og at du har hentet ut koordinatene riktig i Del D.
Del F: plot jordskjelvdata og kystlinjer sammen
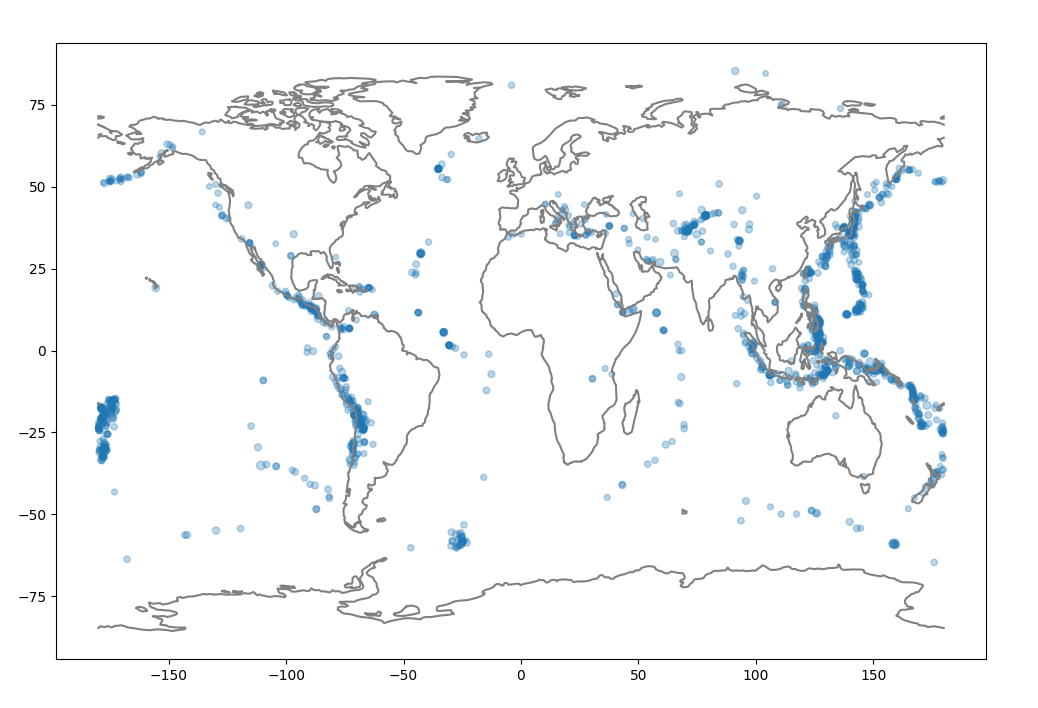
Nå har vi laget alt vi trenger for å plotte jordskjelv og kystlinjer sammen. Vi skal gjøre dette i if __name__ == '__main__'-biten som vi har brukt så langt. Kommenter inn igjen plot_earthquakes-kallet. Før du har kalt på funksjonene som plotter kystlinjer og jordskjelv, bruk plt.figure(figsize=(12,8)) for å lage en ny figur med størrelse 12x8. Dette er for å få et bedre perspektiv på jordskjelvene i forhold til kystlinjene. Legg også til et rutenett. Husk at plt.show() skal kalles etter alt annet for å vise plottet.
Når programmet ditt produserer noe tilsvarende dette, så er du i mål!
- Opprett en ny figur med
plt.figureog størrelsefigsize=(10,6). - Bruk funksjonene fra del A/B og D til å hente ut jordskjelvdata og kystlinjer.
- Plot jordskjelvdata og kystlinjer ved å bruke funksjonene fra del B og D med dataen over.
- Sett tittel på plottet med
plt.title. - Legg til et rutenett med
plt.grid(True). - Kall
plt.show()for å vise plottet.
Valgfri
Kombinere CSV-filer
I denne oppgaven skal vi bruke CSV- biblioteket til å håndtere CSV-filer. Derfor bør du lese om dette i kursnotatene om csv
I denne oppgaven skal vi kombinere flere CSV-filer som ligger i en mappe til én stor CSV-fil. Hver av CSV-filene har det samme formatet, som også er det formatet den kombinerte CSV-filen skal ha:
uibid,karakter,kommentar
abc101,A,"Veldig bra, fra start til slutt"
abc102,B,"Denne kandidaten kan sin INF100, men bommer litt i oppgave 2 og 3"
abc103,C,"Denne kandidaten valgte å kun svare på partallsoppgavene"
I csv_combiner.py skriv en funksjon combine_csv_in_dir(dirpath, result_path) som har to parametre:
dirpather en sti til en mappe som inneholder en rekke CSV-filer som skal kombineres. Det er kun filene som slutter på .csv i mappen som skal inkluderes, andre filtyper skal vi overse.result_pather en sti til en CSV-fil som skal opprettes, som inneholder de kombinerte dataene fra alle CSV-filene.
For å teste funksjonen kan du laste ned samples.zip og pakke ut innholdet i samme mappe hvor du også finner csv_combiner.py. Innholdet skal ligge i en mappe som heter samples. Du kan så teste funksjonen din med denne koden:
print("Tester combine_csv_in_dir... ", end="")
# Mappen samples må ligge i samme mappe som denne filen
dirpath = os.path.join(os.path.dirname(__file__), "samples")
combine_csv_in_dir(dirpath, "combined_table.csv")
with open("combined_table.csv", "rt", encoding='utf-8') as f:
content = f.read()
assert("""\
uibid,karakter,kommentar
abc104,C,hei
abc105,D,"med komma, her er jeg"
abc106,E,tittit
abc101,A,Her er min kommentar
abc102,B,"Jeg er glad, men her er komma"
abc103,C,Katching
""" == content or """\
uibid,karakter,kommentar
abc101,A,Her er min kommentar
abc102,B,"Jeg er glad, men her er komma"
abc103,C,Katching
abc104,C,hei
abc105,D,"med komma, her er jeg"
abc106,E,tittit
""" == content)
print("OK")
Merk: csv-biblioteket sin standard oppførsel når du lagrer 2D-lister som CSV er at det kun benyttes hermetegn dersom det er nødvendig. Det er nødvendig med hermetegn dersom en celle inneholder skilletegn (komma), linjeskift eller hermetegn. Dersom cellen ikke inneholder noen av de tre tegnene, vil det ikke inkluderes hermetegn i filen. Denne oppførselen kan endres ved å kalle på write_csv_file -funksjonen i kursnotatene med argumentene quoting=csv.QUOTE_NONNUMERIC eller quoting=csv.QUOTE_ALL (se også offisiell dokumentasjon).
Dette betyr at selv om det kanskje er hermetegn i input-filen, vil disse ikke nødvendigvis bli med i resultat-filen. Assert-setningene over viser resultatet slik det blir med standard-innstillingene til csv-biblioteket.
-
CSV-filene i dette eksempelet er best lest med csv-biblioteket. Det blir fort komplisert å tolke dem selv, siden det kan være komma-tegn i kommentar-feltet.
-
Les om
os-modulen, og legg spesielt merke tilos.walk-funksjonen. -
Bruk gjerne en hjelpefunksjon
merge_table_into(master_table, new_table)som tar som input en 2D-listemaster_tablesom skal muteres, og en 2D-listenew_tablesom inneholder det nye innholdet som skal legges til. For hver rad i new_table (bortsett fra første rad), kopier raden inn i master_table.
-
Opprett først en 2D-liste for resultat-tabellen vår, som initielt inneholder én rad (overskriftene). På slutten skal vi konvertere denne listen til CSV.
-
Bruk
os.walkelleros.listdirfor å gå igjennom alle filene i mappen gitt veddirpath(os.walk vil også gå inn i undermapper, og du trenger en nøstet løkke inne i os.walk for å gå gjennom listen med filer; ellers fungerer de nokså likt). For hver fil som ender på .csv (bruk f. eks..endswith-metoden på strenger), åpne filen og les innholdet. -
Husk å bruke
os.path.join-funksjonen for å omgjøre filnavn til filstier. -
For hver .csv -fil du finner, omgjør den til en 2D-liste, og legg til radene i resultat-tabellen (bruk hjelpefunksjonen beskrevet over).
Pi med tilfeldige tall
I denne oppgaven skal vi bruke modulen random fra python sitt standardbibliotek for å beregne verdien av \(\pi\). Selvfølgelig finnes en tilnærming for denne verdien allerede (f. eks. math.pi), men la oss forestille oss at vi nå ikke hadde denne beregningen fra før.
Den beste tilnærmingen vi har til π i skrivende stund inneholder over \(10^{12}\) siffer. I python er tilnærmingen av gitt ved
math.pibegrenset til de første 15 siffrene av pi, men det finnes også andre moduler som gir en bedre tilnærming; men da må vi slutte å brukefloat, og heller bruke en annen datatype som er i stand til å gi oss høyere presisjon.
\(\pi\) er definert som en sirkels omkrets delt på sin diameter. Uten å vite nøyaktig hvilken verdi π har, kan matematikere bevise at denne verdien, om vi en vakker dag skulle få vite hva den er, kan brukes for å regne ut en sirkel sitt areal:
$$ A = \pi \cdot r^2 $$
I formelen over er \(r\) sirkelens radius.
Tenk deg nå at vi har en sirkel med sentrum i (0, 0) og radius \(r = 1\). Vi har også et kvadrat med sidelengde \(s = 2\), som går mellom punktene (-1, -1) og (1, 1), som illustrert i bildet under.
 |
| Vi legger verdiene for r og s inn i formelene for areal av henholdsvis sirkler og kvadrat, og får følgende: |
$$A_{\bigcirc} = \pi \cdot r^2 = \pi \cdot 1^2 = \pi$$ $$A_{\square} = s^2 = 2^2 = 4$$
Siden arealet av sirkelen tydelig er mindre enn arealet av kvadratet, vet vi allerede nå at π må være mindre enn 4. Men vi kan gjøre en bedre tilnærming enn som så.
Dersom vi velger et helt tilfeldig punkt inne i kvadratet, vil punktet med viss sannsynlighet \(p\) havne inne i sirkelen. Merk at denne sannsynligheten \(p\) er gitt ved forholdet mellom arealet av sirkelen og kvadratet:
$$ p = \frac{A_{\bigcirc}}{A_{\square}} = \frac{\pi}{4}$$
Det følger at hvis vi klarer å beregne hva \(p\) er for noe, kan vi bare gange tallet med 4 for å finne \(\pi\). Det leder oss til følgende algoritme:
- Gjett et tilfeldig punkt mellom (-1, -1) og (1, 1)
- Sjekk om punktet er innenfor eller utenfor sirkelen
- Gjenta steg 1-2 tilstrekkelig mange ganger, og tell opp hvor ofte det tilfeldige tallet havnet inne i eller utenfor sirkelen. Da bli forholdet mellom antall treff i sirkel og totalt antall genererte punkter tilnærmet lik \(p\).
- Gang opp \(p\) med 4 for å finne en tilnærmet verdi for π.
I random_pi.py skriv en funksjon estimate_pi(n). La funksjonen beregne \(\pi\) ved å generere n tilfeldige koordinater mellom (-1, -1) og (1, 1) og telle opp hvor mange av dem som havnet innefor sirkelen og hvor mange som havnet utenfor.
For å finne et tilfeldig verdi mellom -1 og 1:
random.random()gir oss et tilfeldig flyttall mellom 0 og 1- gang tallet med 2 og trekk fra 1; da får vi et tilfeldig tall mellom -1 og 1. For å finne ut om et punkt er inne i en sirkel, holder det å sjekke om avstanden mellom punktet og sirkelens sentrum er større enn sirkelens radius. Til dette kan vi bruke pytagoras. For å finne avstanden mellom to punkter (x_1, y_1) og (x_2, y_2) bruker vi formelen:
$$ d = \sqrt{(x_2 - x_1)^2 + (y_2 - y_1)^2} $$
Terningkast
I filen, dice_throw.py skal du skrive to funksjoner:
-
Skriv en funksjon
throw_n_2(n)som har som parameter et heltallnog simulerer \(n\) kast av to terninger (bruk modulenrandomfra python sitt standardbibliotek) og legger til summen av de to i en liste. Returner den listen (som nå inneholder \(n\) elementer med tall mellom 2 og 12). -
Skriv så en funksjon
print_histo(throws)som tar inn en slik listethrowsog printer ut et enkelt histogram hvor ‘*’ står for 1% (runde av til nærmeste heltall når prosentandelen av et utfall er et blandet tall). Bruk et oppslagsverk til å telle forekomster av hvert tall. Et kall tilprint_histo(throw_n_2(100))skal for eksempel se noenlunde slik ut (Pass på formateringen av tallene og mellomrom; bruk tab, “\t”, mellom tallene og stjernene):
2 ***
3 ****
4 ******
5 *****
6 ***************
7 **********************
8 ********************
9 *************
10 ********
11 **
12 **
Ikke bruk random.seed() i denne oppgaven slik at autotestene kan fungere rett.
Kvittering
I filen receipt.py skal du bruke modulen decimal. til å skrive et program som produserer en kvittering fra en butikk.
Koden din vil sannsynligvis ikke fungere hvis du ikke bruker decimal-modulen for å lagre tall, siden avrundingsfeil er veldig viktig å unngå, samtidig som vi skal bruke desimal-tall.
Ta utgangspunt i koden nedenfor:
def receipt_content(prices_filename, cash_register_filename):
"""Construct contents of a receipt of the cash register events,
given the store prices."""
# din kode her
def receipt(prices_filename, cash_register_filename):
"""Construct a receipt of the cash register events,
given the store prices."""
# get receipt content from receipt_content()
purchases_returns, total, vat, payment, change = receipt_content(
prices_filename, cash_register_filename
)
# the formatted lines of the receipt
receipt_lines = [f"{'Nr.':>4} {'Item':18} {'Price':>10}"]
for nr, item, price in purchases_returns:
receipt_lines.append(f"{nr:4d} {item:18} {price:10.2f}")
receipt_lines.append(f"Total: {total}")
receipt_lines.append(f"Of which VAT: {vat:.2f}")
receipt_lines.append(f"Payment: {payment}")
receipt_lines.append(f"Change {change}")
# add some dividers
max_len = max(len(line) for line in receipt_lines)
divider = "-" * max_len
receipt_lines.insert(1, divider)
receipt_lines.insert(-4, divider)
receipt_lines.insert(-2, divider)
return "\n".join(receipt_lines)
Du skal skrive koden til funksjonen receipt_content() som beregner inneholdet i kvitteringen utifra en fil med butikkens priser og en fil med hendelsene ved kassen. Argumentet prices_filename er en streng med navnet til filen som inneholder prisene. Argumentet cash_register_filename er en streng med navnet til filen som inneholder hendelsene ved kassen.
Funksjonen receipt_content() skal returnere en tupel som inneholder følgende (i denne rekkefølgen):
- En liste med tupler som inneholder (i følgende rekkefølge) antall, produkt og total pris, først for alle ting som har blitt kjøpt, i alfabetisk orden, og så for alle ting som har blitt returnert, i alfabetisk orden (se eksempelkvittering nedenfor). For de returnerte produktene blir det negative tall.
- Den totale prisen.
- Hvor mye av den totale prisen som er mva.
- Hvor mye som har blitt betalt.
- Hvor mye som blir betalt tilbake (her blir det ikke-positive tall).
Filen med butikkens priser er formattert slik som eksempelfilen prices.txt (som du kan bruke til å teste programmet ditt). Først står produkt, så semikolon (;), og så prisen. Dette er egentlig en CSV-fil som bruker semikolon som skilletegn.
Filen med hendelsene ved kassen er formattert slik som eksempelfilen cash_register.txt (som du kan bruke til å teste programmet ditt). Først står hva som skjer (kjøp, retur eller betaling), så semikolon (;), og så produkten/verdien. Dette er også egentlig en CSV-fil som bruker semikolon som skilletegn.
Funksjonen receipt() skal du ikke endre. Den bruker receipt_content() til å beregne inneholdet i kvitteringen og så produserer receipt() en pen kvittering utifra det innholdet. Du skal bare skrive kode til receipt_content().
Om din kode til receipt_content() er riktig så skal denne testen passere:
print("Tester receipt... ", end="")
expected_value = """\
Nr. Item Price
------------------------------------
2 apple 10.00
1 chips 24.30
1 dish soap 26.20
1 frozen pizza 54.40
1 peanuts 18.50
1 toilet paper 34.00
3 tomato 30.00
-1 pocket book -149.00
-1 toothpaste -13.70
------------------------------------
Total: 34.70
Of which VAT: 6.94
------------------------------------
Payment: 100.00
Change -65.30"""
assert(expected_value == receipt("prices.txt", "cash_register.txt"))
print("OK")
-
Du må bruke biblioteket decimal for at beregningene skal bli riktige (prøv hvordan kvitteringen blir om du bruker float).
-
Decimal aksepterer både float og string for å lage decimals. Prøv hvordan kvitteringen blir om du gir decimals en float. Hvorfor skjer dette?
-
Det er mulig at betaling skjer flere ganger underveis ved kassen.
-
Du kan anta at alle betalinger ved kassen har positiv verdi.
-
Du kan anta at det ikke er noen feil i filene som inneholder prisene og hendelsene ved kassen.
-
Det er mulig at den totale prisen blir negativt (om kunden for eksempel bare returnerer ting).
-
Gitt en pris inklusive mva så multipliserer du prisen med 0.2 for å finne ut hvor mye av prisen som er mva.
-
Det kan være lurt å bruke dictionaries til prislisten og det som blitt kjøpt og det som blitt returnert.
-
Du må ikke skrive all kode innen funksjonen
receipt_content(). Du kan dele opp koden i flere funksjoner på en måte du synes føles naturlig.
Værmelding
I filen forecast.py skriv en funksjon weather_in_bergen_next_hour() uten parametre som returnerer en streng som sammenfatter været i Bergen den neste timen. Funksjonen skal hente vær-data fra meterologisk instutt, og bruke informasjon fra feltet «symbol_code» om den nærmeste timen.
Eksempelkjøring:
print("Været i Bergen neste time:", weather_in_bergen_next_hour())
Været i Bergen neste time: cloudy
For å løse denne oppgaven, skal vi
- Finne ut hvilken url vi kan bruke for å få informasjon om været fra meterologisk institutt
- Bruke requests -pakken for å laste ned informasjonen fra meterlogisk institutt inn i python-programmet
- Bruke json -pakken for å konvertere den nedlastede informasjonen til et oppslagsverk, og til slutt
- Slå opp på riktig sted i oppslagsverket og returnere denne informasjonen.
Steg A: nettadresse fra meterologisk institutt
Meterologisk instutt tilbyr massevis av vær-informasjon gratis (under lisensen CC-BY 4.0) fra sine nettsider. Slå opp på nettsiden https://api.met.no/weatherapi/locationforecast/2.0/ og finn OPENAPI UI fannen (Øverst i siden ved siden av DOCUMENTATION). Les om GET /compact under data.
- Du vil under «parameters» se to felter lat og lon hvor du kan fylle ut henholdsvis breddegrad og lengdegrad for hvilken posisjon du ønsker.
For å finne breddegrad og lengdegrad for et gitt sted, kan du på til https://maps.google.com og trykke på kartet. Da vil koordinatene til det gitte stedet vises.
- Når du har fylt ut breddegrad og lengdegrad, trykk på «Try it out!»
- Kopier med deg internettadressen under «Request URL». Dette er adressen til siden vi skal laste ned i programmet vårt (prøv den direkte i nettleseren også og se hva du får).
- Undersøk innholdet under «Response Body». Dette er den strengen vi får når vi laster ned innholdet fra den overnevnte nettadressen. Hvor ligger informasjonen vi er ute etter? Husk, vi ser etter verdier knyttet til nøkkelen «symbol_code».
Steg B: bruk requests for å laste ned informasjon
Bruk nettadressen vi fant i forrige steg som url. Merk at vilkårene til Meterologisk institutt sier at vi må identifisere hvem vi er i User-Agent -feltet i «header». Det er tilstrekkelig å bruke "inf100.ii.uib.no <ditt uib-brukernavn>" som verdi for dette feltet.
Steg C: bruk JSON for å konvertere til oppslagsverk
Du kan bruke json.loads() for å konvertere en streng til et oppslagsverk. Her er et eksempel på hvordan du kan gjøre det:
import json
s = '{"a": 1, "b": 2}'
d = json.loads(s)
print(d["a"]) # 1
Her blir d et oppslagsverk med nøklene “a” og “b” og verdiene 1 og 2.
Steg D: returner verdien knyttet til nøkkelen «symbol code» i oppslagsverket
Det gjelder å holde tungen rett i munnen når du skal slå opp i oppslagsverket. En strategi kan være å begynne med å returnere d["properties"] og så spesifisere videre ved å returnere d["properties"]["timeseries"] og så videre, helt til riktig verdi blir returnert.
Det er ikke nødvendig å finne nøyaktig riktig time for å få oppgaven godkjent, det holder å returnere den første timen du får informasjon om (selv om den var i fortiden)
Steg E (frivillig): finn nøyaktig riktig time å rapportere for
For å rapportere for nøyaktig riktig time, må du matche den timen du får fra meterologisk instiutt med tiden akkurat nå. Les deg opp på datetime -modulen og se om du kan bruke informasjonen fra meterologisk institutt for å finne den nærmeste timen å rapportere fra.
Steg F (frivillig): mer omfattende værmelding
Kan du finne mer informasjon å rapportere? Nedbørsmengder? Vind? Sannsynlighet for nedbør (nå må du over på GET /complete hos meterologisk institutt)?